浅谈数据库分表分库策略
更新日期:
随着大数据时代的来临,数据的存储和访问成了系统设计的瓶颈。对于一个大型的互联网项目,每天百万,千万的访问量都是正常的现象。那么这么频繁的通讯,无疑会给服务器的访问速度和稳定性带来了巨大的鸭梨。那么我们的聪明的计算机专家们是不是束手无策了了。答案肯定是NO。我们的计算机工程师们立马就想出了对策。分表,分库。一种新的概念立马在软件行业里面产生巨大的反响。有了这种方式在面对海量数据的时候我们的系统仍然能够支撑的起来。既然谈到了分表分库那么下面我们就先来理解一下什么是分表,分库的概念。
分表分库的概念:
分表,分库通俗的解释就是原来一个人完成的事情我们现在让两个人一起来完成。专业的解释就是数据的切分“Sharding”(可以理解为分片的意思),要说切菜,切肉我知道,但是切数据是什么意思了又该怎么去切了。好了 下面我们就简单的解释下什么是数据的切分(Date Sharding)
所谓的数据切分就是通过一系列的切分规则将数据分布到不同的DB或者Table中。再通过相应的DB路由或者Table路由的规则找到这些数据所在的DB或Table。进行数据的“增删改查”等一序列的操作。
那么在了解了数据切分的概念后我们来说说数据的切分有那些方式,主要有两种,一种是物理上的,一种是逻辑上的。那么什么物理上的切分,什么又叫做逻辑上的切分了。
物理切分:物理上的切分就是通过既定的切分规则将数据分布到不同的DB上去,通过路由访问规则去访问这些特定的数据库。这样我们每次的访问就不止访问一台服务器了,而是多台。
例如:我们的系统需要把会员表(user)进行无物理上的切分,那么我们就可以把id为1-1000放进DB1里面,把id为1001-2000放进DB2里面,把id为2001-3000放在DB3中。当然还需要在DB1中建立一张路由表(regulation),用来描述切分规则
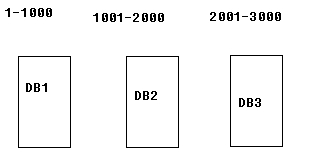
逻辑切分:逻辑切分就好理解了,它就是通过既定切分规则,将数据分布到同一个数据库的不同的表里面。然后通过路由表的规则找到这些数据在那张表。然后对数据进行一些了的操作。
例如:同样我们要对会有表(user)进行分表的处理。这次我们采用逻辑上切分,那么这个时候我们还是跟上次的切分规则一样id为1-1000的在user1,id为1001-2000的在user2。然后建立张路由表(regulation)来记录这些信息。
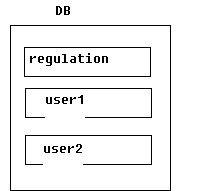
那么在了解了分表分库的概念后,接下来我们就来了解下分表的方案,因为分表的方式有很多中,没有那种更好,只有那种更适合我当前的场景。但是原理都一样,即添加信息路由机制,但是有二个原则一个是分表方案执行速度要快,另一个是一个博客的信息必须要保存在一张分表中,以有利于信息查找。这里提供三种分表方案:
(1) 方案一、将表ID设置成一个自动自增主键,那么我们就可以把每个表的初始ID记录在配置文件里,这样我们的程序就很容易根据ID找到对应的数据表了。这种方法没有数据大规模迁移的麻烦,可是每个表的访问压力会有比较大的差别。
(2) 方案二、使用信息路由机制,给每一个要进行分表的表建一个路由表,表结构如下

方案2的访问机制如下
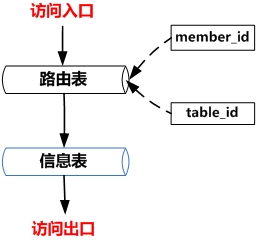
我们首先要根据会员的id在路由表里面找到会员信息所处的表名,然后对信息进行查询。采用这种机制需要开发一个自动分表程序,然后让自动分表程序每隔一段时间就执行一次,如果最后一个分表超过了设定的信息最大值,就进行分表,这个分表机制适合每一个会员的信息量都相差不大情况。
1) 方案三、建立带有统计功能的信息路由机制,这种机制和第二种方案类似,但是在方案二的基础上再增加了一张信息统计表,统计某一个会员在分表中的信息总量,表结构如下:
在分表的时候会将当前表中信息量最大的一个或几个会员的信息提取出来,放到新的分表中,以减慢当前表信息的增长速度,这种机制适合于有的会员的信息量很大,更新也很频繁的情况。
方案三信息访问机制如下
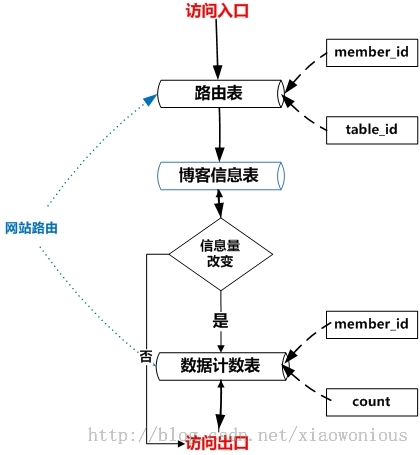
当然,分表分库这些方法虽然能承载巨大的数据也不是没有缺点的,比我我们在做联合查询的时候,有可能就无法实现,因为有些关联数据会不在同一个库里面,所以我们要尽量把有关联的数据放在同一种个DB里面。还要尽量避免跨库的事物。
转载自:CSDN博客