Java HashMap工作原理及实现(Jdk8)
更新日期:
1. 概述
- 什么时候会使用HashMap?他有什么特点?
- 你知道HashMap的工作原理吗?
- 你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
- 你知道hash的实现吗?为什么要这样实现?
- 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
当我们执行下面的操作时:
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("语文", 1);
map.put("数学", 2);
map.put("英语", 3);
map.put("历史", 4);
map.put("政治", 5);
map.put("地理", 6);
map.put("生物", 7);
map.put("化学", 8);
for(Entry<String, Integer> entry : lmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
运行结果是
政治: 5
生物: 7
历史: 4
数学: 2
化学: 8
语文: 1
英语: 3
地理: 6
发生了什么呢?下面是一个大致的结构,希望我们对HashMap的结构有一个感性的认识:
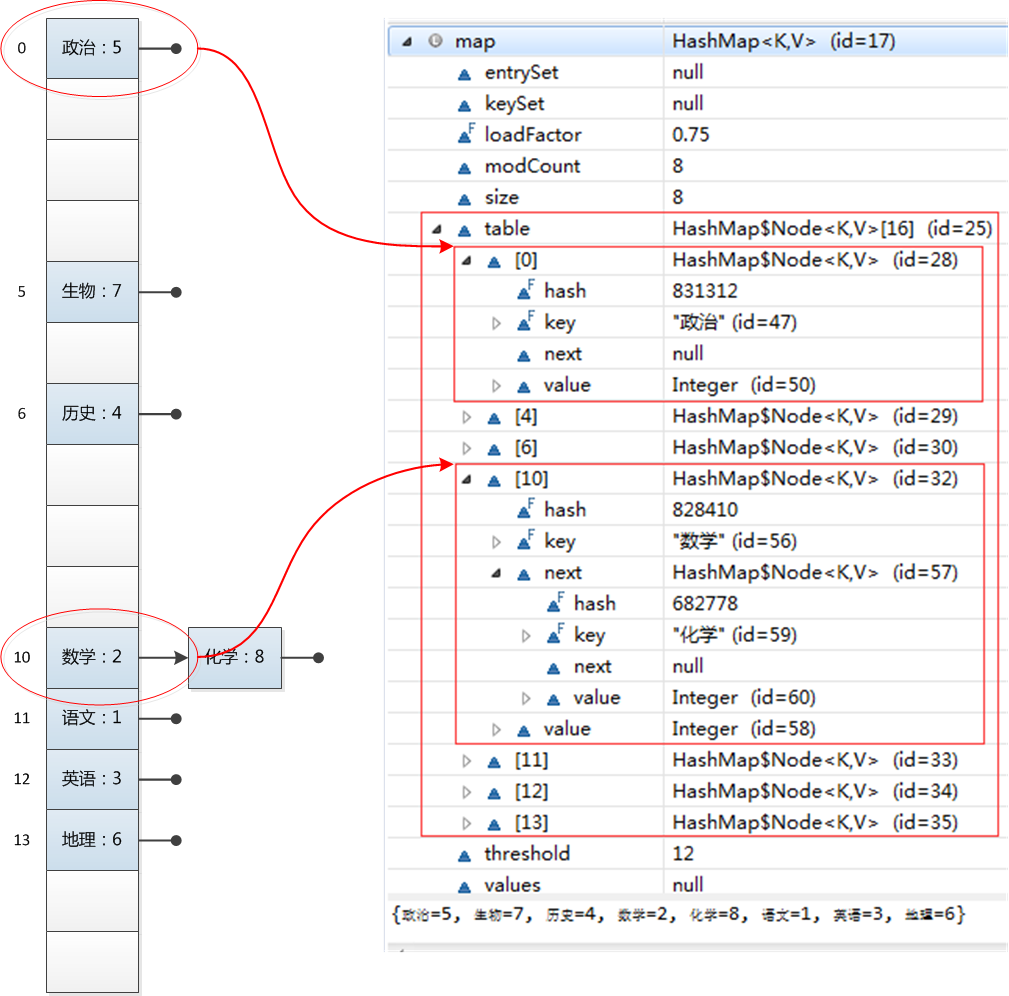
在官方文档中是这样描述HashMap的:
Hash table based implementation of the Map interface. This implementation provides all of the optional map
operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable,
except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map;
in particular, it does not guarantee that the order will remain constant over time.
几个关键的信息:基于Map接口实现、允许null键/值、非同步、不保证有序(比如插入的顺序)、也不保证序不随时间变化。
2. 两个重要的参数
在HashMap中有两个很重要的参数,容量(Capacity)和负载因子(Load factor)
- Initial capacity The capacity is the number of buckets in the hash table, The initial capacity is simply the capacity at the time the hash table is created.
- Load factor The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
简单的说,Capacity就是bucket的大小,Load factor就是bucket填满程度的最大比例。如果对迭代性能要求很高的话不要把capacity设置过大,也不要把load factor设置过小。当bucket中的entries的数目大于capacity*load factor时就需要调整bucket的大小为当前的2倍
3. put函数的实现
put函数大致的思路为:
- 对key的hashCode()做hash,然后再计算index;
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
具体代码的实现如下:
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 节点存在
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该链为树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 写入
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过load factor*current capacity,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
4. get函数的实现
在理解了put之后,get就很简单了。大致思路如下:
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的entry若为树,则在树中通过key.equals(k)查找,O(logn);
若为链表,则在链表中通过key.equals(k)查找,O(n)。
具体代码的实现如下:
具体代码的实现如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
5. hash函数的实现
在get和put的过程中,计算下标时,先对hashCode进行hash操作,然后再通过hash值进一步计算下标,如下图所示:

static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
可以看到这个函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或。其中代码注释是这样写的:
Computes key.hashCode() and spreads (XORs) higher bits of hash to lower. Because the table uses power-of-two
masking, sets of hashes that vary only in bits above the current mask will always collide. (Among known
examples are sets of Float keys holding consecutive whole numbers in small tables.) So we apply a transform
that spreads the impact of higher bits downward. There is a tradeoff between speed, utility, and quality of
bit-spreading. Because many common sets of hashes are already reasonably distributed (so don’t benefit from
spreading), and because we use trees to handle large sets of collisions in bins, we just XOR some shifted bits
in the cheapest possible way to reduce systematic lossage, as well as to incorporate impact of the highest bits
that would otherwise never be used in index calculations because of table bounds.